无
”中文词频 统计 Python“ 的搜索结果
今天,我们总结了四种常见的中文词频统计方法,并列出代码,供大家学习参考。中文词频统计主要是通过open()打开文本,然后read()方法读取后,采用结巴分词(jieba)模块进行分词,接着用推表推导式、Counter或者是字典...
以下是关于小说的中文词频统计 这里有三个文件,分别为novel.txt、punctuation.txt、meaningless.txt。 这三个是小说文本、特殊符号和无意义词
说明:运用集合对文本字符串列表去重,这样统计词汇不会重复,运用列表的counts方法统计频数,将每个词汇和其出现的次数打包成一个列表加入到word_list中,运用列表的sort方法排序,大功告成。

本文介绍了python实现简单中文词频统计示例,分享给大家,具体如下: 任务 简单统计一个小说中哪些个汉字出现的频率最高 知识点 1.文件操作 2.字典 3.排序 4.lambda 代码 import codecs import matplotlib.pyplot ...

1. 下载一长篇中文小说。2. 从文件读取待分析文本。3. 安装并使用jieba进行中文分词。pip install jiebaimport jiebaljieba.lcut(text)import jiebatxt = open(r'piao.txt','r',encoding='utf-8').read()wordsls=...

python词频统计, 可视化展示使用pyecharts

前面我们已经介绍了文本分析中的中文分词和去除停用词,这篇文章将详细介绍分词后如何进行词频统计分析。


Python词频统计
标签: python

以下是一个简单的中文词频统计 Python 代码: ```python import jieba # 打开文件 with open('input.txt', 'r', encoding='utf-8') as f: text = f.read() # 切分文本 words = jieba.cut(text) # 计算词频 word...
安徽工程大学Python程序设计班级:物流191姓名:汤振宇学号:319050108成绩:日期:...1)水浒传词频统计水浒传-词频统计描述使用词频统计的方法,生成《水浒传》出场次数最多的10个人物的姓名。...

1、利用字典dict来完成统计#举例:a = [1 2 3 1 1 2]dict = {}for key in a:dict[key] = dict.get(key 0) + 1 #字典的get函数可以查询键的值,0代表默认值每出现一次加1print (dict)输出结果: >>>{1: 3 2: 2 3: 1}2...
Python中英文词频统计
标签: python
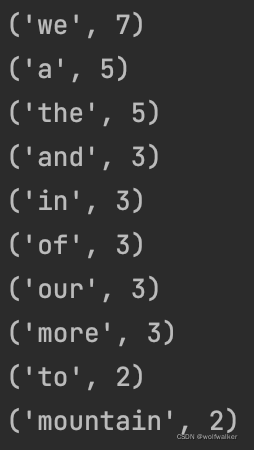
python学习文本词频统计hamlet.txt三国演义.txt

上市公司年报_Python中jieba_数字化_关键词词频统计_程序+样例


(有一些是安装好python电脑自带有哦)有一些会出现一种情况就是安装不了词云展示库有下面解决方法,需看请复制链接查看:https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud第三步:1.准备好你打算统计的文件...

以下是关于小说的中文词频统计这里有三个文件,分别为novel.txt、punctuation.txt、meaningless.txt。这三个是小说文本、特殊符号和无意义词Python代码统计词频如下:import jieba # jieba中文分词库# 从文件读入...
在学习了组合数据类型和文件操作之后就可以做出下面的文本词频统计的小程序了:1. 下面是英文文本的词频统计,统计了作者的一篇英文论文#文本词频统计:英文文本def gettext():#从文件中获取文本text = open("target...
需要统计一本小说中某个人(主角)名字,或者某个关键词在文章中出现的次数,由于字数太多我们不可能人为的慢慢去计数,这时我们可以根据程序来自动获得其次数。...Python实现英文词频统计。简单高效实用字典几行代码
推荐文章
- Python字典类型及操作_字典是键值对的结合,键值对之间没有顺序。-程序员宅基地
- shader学习集锦-程序员宅基地
- python 一个整数,它加上100后是一个完全平方数,再加上168又是一个完全平方数,请问该数是多少?_一个整数,它加上100后是一个完全平方数,再加上168又是一个完全平方数,请问该数是-程序员宅基地
- Linux时间子系统之六:高精度定时器(HRTIMER)的原理和实现 ._timekeeping_delta_to_ns-程序员宅基地
- TTS | 语音合成模型实验结果经验总结_use_duration_discriminator-程序员宅基地
- Android技术框架篇(三):MVVM框架_android mvvm-程序员宅基地
- 第4章c语言作业_c语言第四章作业-程序员宅基地
- PCL1.8+Ubuntu16.04安装详解-程序员宅基地
- win11 文件拖到任务栏无法打开的解决办法_win11文件拖到任务栏打不开-程序员宅基地
- STM32WB55大半年开发记录,血氧心率检测手环-程序员宅基地